Setting parameters in the FEPCluster yaml and applying them creates a Triton inference server. An inference server is the server that actually performs computations based on the model. Using Triton's inference server enables vector transformations utilizing the model. When creating the inference server, a service is also created to facilitate communication between the database server and the inference server. Communication with the inference server can also be encrypted using mutual TLS (mTLS).
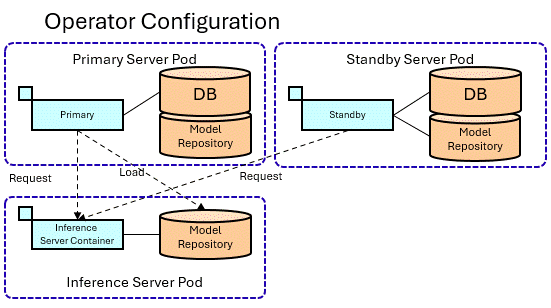
In Operator, inference server Pods are created independently of database server Pods.
Since the inference server Pod also requires a workspace when loading model files, both the inference server Pod and the database server Pod require disk space for the model repository.
The disk to mount on the database server Pod must be defined in the spec.fepChildCrVal.storage.modelRepositoryVol parameter of the FEPCluster custom resource and prepared for each instance.
The disk to be mounted on the inference server Pod is defined in the spec.fepChildCrVal.storage.inferenceVol parameter of the FEPCluster custom resource, and one disk must be prepared.
Allocate the estimated capacity for each disk as specified in the Fujitsu Enterprise Postgres Knowledge Data Management Feature User's Guide.