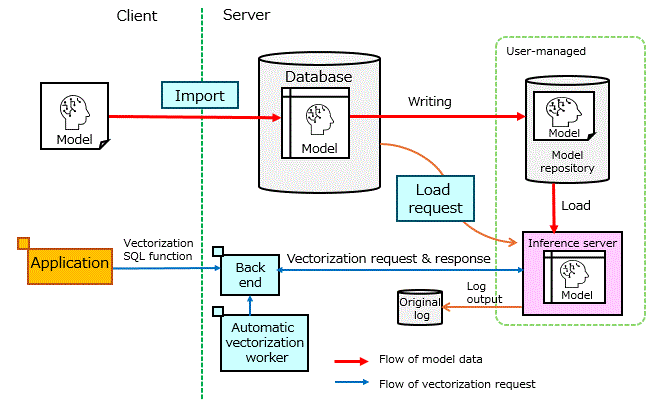
Import the ONNX format text embedding model for vectorization into the database and operate it on an inference server running outside the database. This allows the model to be imported and made available for use through database operations alone, enabling vectorization and semantic text search with the model.
This feature provides an import command as a client feature to INSERT the model file into a table within the database. This operation is called import. After importing the model, a request is executed to make it ready for vectorization using the model. This is called a load request. When a load request is made, the model is loaded onto the inference server, making vectorization using the model possible. The inference server is the server that actually performs calculations based on the model.
Once the model is loaded, vectorization using the model becomes possible. The vectorization process is realized by requesting the inference server to transform text data into vector data and receiving the vector data. The backend process handles the request for vectorization to the inference server and the reception of results.