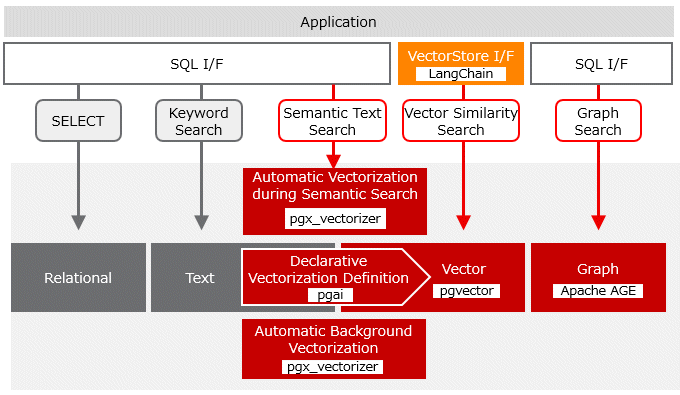
The Knowledge Data Management feature allows you to search based on semantic relationships using vectors and graphs, and manage those data.
When you use a large language model (LLM) in a retrieval-augmented generation (RAG) approach, you need external knowledge data to give to LLM. Fujitsu Enterprise Postgres can manage knowledge data in vector and graph formats, eliminating the need for a dedicated database for each format. You can also use Fujitsu Enterprise Postgres database multiplexing, access control, data encryption, and other features to securely manage your knowledge data.
In addition to existing searches, the Knowledge Data Management feature enables you to search knowledge data in three ways:
Similar search of vector data
Performs a similarity search between the specified vector data and the vector data stored in Fujitsu Enterprise Postgres.
![]() Searching text data based on semantic similarity
Searching text data based on semantic similarity
Searches for semantic similarity between the specified text and the text stored in Fujitsu Enterprise Postgres using embedding in a semantic vector.
When you store text data for semantic search in Fujitsu Enterprise Postgres, a vector (semantic vector) that captures the semantic similarity of the text data is automatically generated and stored in the database. When searching, the specified text data is automatically converted to vector data, and semantic search is performed by the vector similarity search.
![]() Searching graphs based on relationships
Searching graphs based on relationships
A graph is a data structure that represents entities and their relationships as nodes and the edges that connect them. You can search graphs based on properties and relationships.
Knowledge data can be accessed by executing SQL queries from the application to Fujitsu Enterprise Postgres. You can also use LangChain, an AI application development framework, to access knowledge data in Fujitsu Enterprise Postgres.
What the knowledge data management feature can do
The Knowledge Data Management feature enables you to:
Vector data storage and retrieval using the vector data management feature
Storage of float32, float16, bit vectors, and sparse vectors
Vector neighbor search by cosine or euclidean distance
HNSW and IVFFlat vector index
![]() DiskANN-based vector index suitable for large data sets
DiskANN-based vector index suitable for large data sets
![]() Semantic text search and automatic vectorization
Semantic text search and automatic vectorization
Automated background vectorization of newly added text data
Semantic search with automatic query vectorization, consistent with stored vector representation
Use of external vector embedding models such as Ollama and OpenAI
![]() Graph data storage and retrieval using the graph data management feature
Graph data storage and retrieval using the graph data management feature
Storing graphs
Exploring and updating graphs with openCypher
Application development support
LangChain linkage
For access from Python applications using LangChain, refer to the technical documentation available at:
https://www.postgresql.fastware.com/resource-center